(не)структурированные мысли Алексея Тутубалина
Вход на сайт
Свежие комментарии
- 26/Ноя/2022 16:10 Ну так дайте файлов, вы
- 26/Ноя/2022 16:04 > Ну мы не полезем на эту
- 26/Ноя/2022 16:04 ну это потому что его только
- 26/Ноя/2022 11:33 Поскольку я вот про этот
- 26/Ноя/2022 11:32 Ну мы не полезем на эту елку
- 26/Ноя/2022 10:50 вот туда же их маркетинг =
- 26/Ноя/2022 10:47 там есть условно-бесплатный
- 26/Ноя/2022 10:43 https://cam.start.canon/en
- 26/Ноя/2022 09:34 А дайте пример, а то мы о
- 25/Ноя/2022 23:59 А новомодные .CRN файлы от
more
спонсоры проекта
Свежие комментарии
- Ну так дайте файлов, вы 3 years 8 months ago
- > Ну мы не полезем на эту 3 years 8 months ago
- ну это потому что его только 3 years 8 months ago
- Поскольку я вот про этот 3 years 8 months ago
- Ну мы не полезем на эту елку 3 years 8 months ago
- вот туда же их маркетинг = 3 years 8 months ago
- там есть условно-бесплатный 3 years 8 months ago
- https://cam.start.canon/en 3 years 8 months ago
- А дайте пример, а то мы о 3 years 8 months ago
- А новомодные .CRN файлы от 3 years 8 months ago





 Как-то нет сил и времени писать на эту тему полноценных текст, поэтому пока в телеграфном режиме.
Как-то нет сил и времени писать на эту тему полноценных текст, поэтому пока в телеграфном режиме.
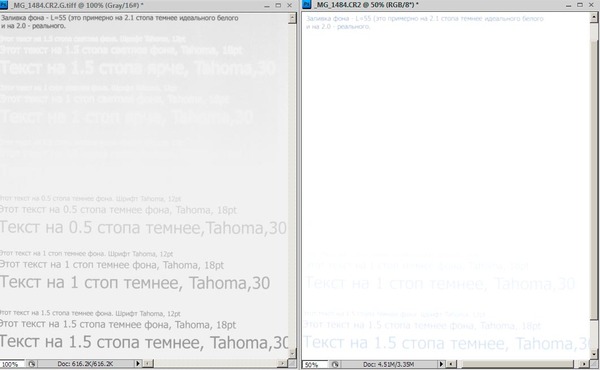
 Смотрю я, значит, на серый фон от
Смотрю я, значит, на серый фон от 
 Эта тема уже , но на качественном уровне. Однако наделанный в последнее время инструментарий позволяет померять эффекты засветки количественно.
Эта тема уже , но на качественном уровне. Однако наделанный в последнее время инструментарий позволяет померять эффекты засветки количественно.
 В комментариях к
В комментариях к 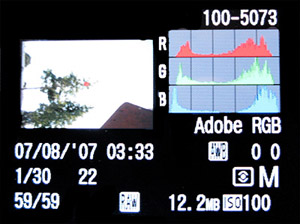 Почему-то никто из комментирующих
Почему-то никто из комментирующих 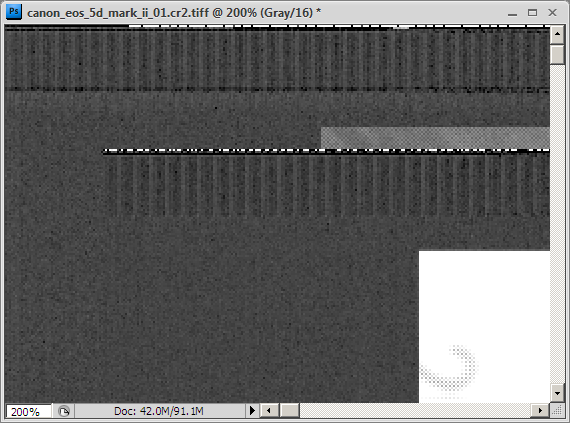
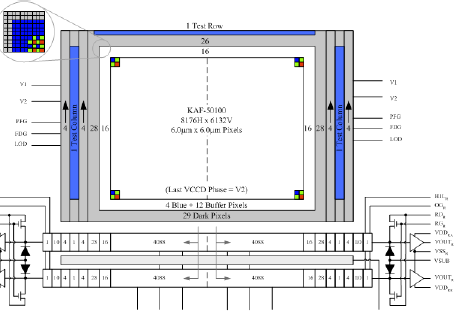 Говоря о RAW-данных ("необработанные", "данные прямо с матрицы") большинство фотографов (да и не только фотографов) полагают, что сенсор - это очень простая штука: массив светочувствительных элементов, цветные фильтры, сбоку прикручен АЦП (или несколько). Появляется в рекламных буклетах производителей фраза "мы уменьшили зазор между микролинзами" - вспоминают еще и про микролинзы. Документации то разумной почти нет. Про острую нужду в кривых спектральной чувствительности мы , но есть острая нужда не только в этих данных.
Говоря о RAW-данных ("необработанные", "данные прямо с матрицы") большинство фотографов (да и не только фотографов) полагают, что сенсор - это очень простая штука: массив светочувствительных элементов, цветные фильтры, сбоку прикручен АЦП (или несколько). Появляется в рекламных буклетах производителей фраза "мы уменьшили зазор между микролинзами" - вспоминают еще и про микролинзы. Документации то разумной почти нет. Про острую нужду в кривых спектральной чувствительности мы , но есть острая нужда не только в этих данных.