Q: Nvidia Kepler (GTX680)
lexa - 23/Мар/2012 13:55
Граждане читатели!
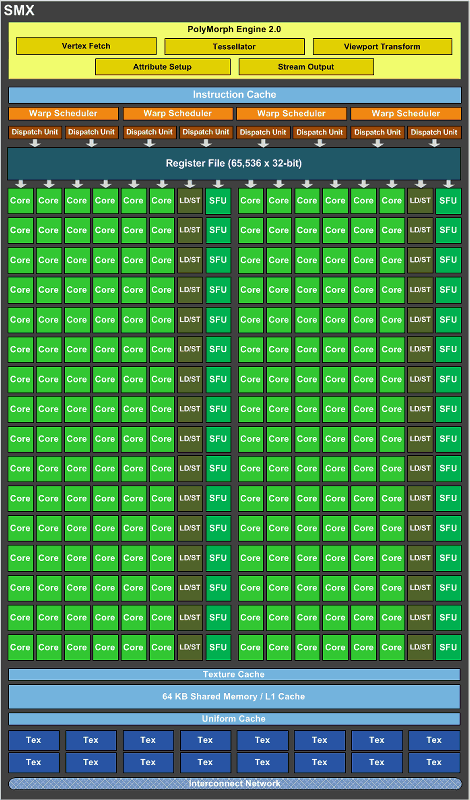
А кто-нибудь может показать пальцем в какие-то разумные документы про вычисления на NV Kepler (она же - анонсированная вчера NVidia GTX 680)?То что я вижу на картинках меня смущает:
{kind=link}
- Количество этих самых "Cuda Cores" учетверили (в сравнении с Compute Capability 2.1) в одном мультипроцессоре с 48 до 192.
- Количество регистров в SM(X) - удвоили, стало 64к вместо 32к.
Количество shared memory - и вовсе оставили прежним (64kb shared+L1 cache)
При этом, Anandtech показывает довольно позорные цифири по GPGPU, причем даже по потоковым DirectCompute, коим shared memory и не нужна. Не, понятно, драйвера свежие и оттого кривые, недодевелопленные, но все-таки.
Ну и второй вопрос: а что там с double? Anandtech пишет про 1/24, дядя шутит? Хотя вот еще клевещут, и получается похоже на 1/24.
Comments
а вот ATI карты без монитора заводятся? у меня было впечетле
а вот ATI карты без монитора заводятся?
у меня было впечетление, что это зависит исключительно от вендора карты, а не чипа (nvidia/ati), а тут nvidia начала пальцы гнуть, что только они умеют.
Тут долгая история. Под виндой: вторую (и более) nvidia-кар
Тут долгая история.
Под виндой:
вторую (и более) nvidia-карту можно обозвать PhysX-устройством. Тогда все GPGPU (Cuda/OpenCL) программы их увидят и будет щастье. В случае если "видео"-карта ATI, а вторая карта (без монитора) - NV, фишка штатно не работает, но ее как-то хакали.
ATI - да, нужно подключение монитора, без монитора у меня не получалось.
Под Linux
ATI: монитор не нужен, а вот Xorg придется запустить (оторвав ему авторизацию, например), драйвера все в иксах.
NVidia: есть compute-драйвера и *вроде бы* они под Linux заводятся и с Geforce тоже. Не пробовал, но читал.
Compute-драйвера есть и для винды, но под виндой они поддерживают только Compute-Карты.
Под маком: не знаю. Всегда подключал монитор(ы)
> "видео"-карта ATI, а вторая карта (без монитора) - NV А в
> "видео"-карта ATI, а вторая карта (без монитора) - NV
А в чем проблема? У меня еще прошлым летом сразу заработала такая конфигурация.
> NVidia: есть compute-драйвера и *вроде бы* они под Linux заводятся и с Geforce тоже. Не пробовал, но читал.
Я опять же прошлым летом поставил обычный драйвер и все заработало.
Проблема завести на NVidia PhysX при наличии в системе ATI.
Проблема завести на NVidia PhysX при наличии в системе ATI. В некотрый момент это было проблемой, возможно потом ограничения ослабили, надо попробовать.
Про PhysX сказать ничего не могу.
Про PhysX сказать ничего не могу.
А тогда как? Если к NV-карте не подключать монитор, то драйв
А тогда как?
Если к NV-карте не подключать монитор, то драйвер в винде - не грузится, карта не видна.
Если мониторов два, один к NV, второй к ATI - проблем нет, сам так живу.
Да, суть проблемы которую я решал: запустить Parallel Nsight
Да, суть проблемы которую я решал: запустить Parallel Nsight на одной машине (с двумя видеокартами). Это совсем нормально делается если отлаживаемая программа работает на PhysX-карте.
> Если к NV-карте не подключать монитор, то драйвер в винде
> Если к NV-карте не подключать монитор, то драйвер в винде - не грузится, карта не видна.
Это странно. У меня дома, повторюсь, все грузилось еще летом. Ну и сейчас работает.
И Parallel Nsight у меня как то работал, в том смысле, что вся функциональность, доступная для OpenCL программ, работала. А CUDA я тогда не пробовал.
Я сейчас попробовал - да, поведение совсем другое, чем было
Я сейчас попробовал - да, поведение совсем другое, чем было (а предыдущие разы я пробовал года три уже назад, когда 5870 купил).
Если сейчас отключить монитор (и даже перезагрузиться), то весь десктоп остается на карте с отключенным монитором (на другую карту -другой монитор не переезжает) и вообще все как-то не так, как было раньше.
Драйвера 296.10
Совсем по хорошему, надо это изучить, потому что если можно NV-картой пользоваться не подключая к ней мониторов и не расширяя на нее десктоп, то этом может быть удобно.
Проблема в том, что у ATI7970 (вторая моя карта) только один DVI выход, а у меня все мониторы - DVI. Вроде переходник был в той коробке, поищу.
У AMD в 7000 серии отличается
У AMD в 7000 серии отличается отношения double/sigle для серий 77xx, 78xx, x79xx?
Ну вот по последней ссылке
Ну вот по последней ссылке (про "клевещут") читаем "Even the Radeon HD 7870 with its restricted double precision floating-point"
Ну то есть 7870 (по той бенчмарке) в 1.5 раза медленнее 7970 в Single и в ~8 раз в Double.
Судя по табличке на radeon.ru, у 79-й серии отношение 1:4, а у 78/77 - 1:16
Нет,пока, таких документов.Все авторы обзоров либо считают
Нет,пока, таких документов.Все авторы обзоров либо считают сами,либо пишут что nvidia позже предоставит данные.
Регистры отскейлены нормально (не забывайте про отсутствие у
Регистры отскейлены нормально (не забывайте про отсутствие удвоенной частоты, на которой раньше работали ALU). Разделяемая память/L1 - да, не отскейлены. Текстурный кеш в помощь.
В том смысле, что новые 192 cores - это как старые 96? Ско
В том смысле, что новые 192 cores - это как старые 96?
Сколько потоков (в максимуме) может исполнять один SMX, и сколько их надо, чтобы спрятать латентность RAM?
Алекс, я отметил, что в Вашей трактовке публичного слайда ес
Алекс, я отметил, что в Вашей трактовке публичного слайда есть неточности. К сожалению, я не могу (не имею права) комментировать Ваши другие предположения.
OK, хорошо, подождем каких-то официальных текстов. Все одно
OK, хорошо, подождем каких-то официальных текстов.
Все одно, тестировать пока не на чем, в продаже у нас - в лучшем случае через месяц.
Да, посмотрел в ваш журнал, увидел вот это <i>С понедельника
Да, посмотрел в ваш журнал, увидел вот это С понедельника я выхожу на работу в NVidia.
Больше задавать неприятных вопросов не буду. Не знал.
О, да ничего страшного.
О, да ничего страшного.
Отвечаю сам себе (чтобы тут было): 2048 потоков. Про латент
Отвечаю сам себе (чтобы тут было): 2048 потоков. Про латентность непонятно, в доке написано пока мало.
Источник Where do I get CUDA toolkits for GeForce GTX 680? - там CUDA 4.2 beta, в приложениях в доке написана пара страниц про GTX 680.
Ну то есть если мы весь SM(X) набиваем потоками под завязку (с целью спрятать латентность), получается, если я не обсчитался, 32 регистра на поток. Что даже больше, чем у Fermi (32k регистров на 1536 потоков - 20 на поток). Зря, получается, обидел NV.
Скажите пожалуйста а Parallel
Скажите пожалуйста а Parallel Nsight, как переключается с GPU на CPU?
Что-то меделенно стал работатьать
Спасибо