NVidia 8800GTX: скорость чтения текстур
В то же время, скорость доступа при неоптимальном паттерне очень маленькая. Для решения этой проблемы (помимо оптимизации паттерна) NVidia CUDA предлагает доступ к памяти как к текстуре. При этом работает двумерное кэширование (оптимизированное под локальный доступ), пиковые скорости должны получаться меньше, а наихудшие варианты - наоборот лучше.
Все это, как обычно, нуждается в изучении.
Тестовая задача
Тестовая задача практически неотличима от предыдущего варианта, но вместо доступа к массиву по индексу используется texfetch:__global__ void
Sum_h(int run,FTYPE *g_idata, float *g_odata)
{
const unsigned int blocks = gridDim.x;
const unsigned int threads = blockDim.x;
const unsigned int tid = threadIdx.x;
const unsigned int bx = blockIdx.x;
unsigned int rowN,colN;
float sum = 0.0;
for(rowN=bx; rowN < SIZE; rowN+=blocks){
for(colN=tid; colN < SIZE; colN+=threads){
sum += texfetch(tex,rowN,colN);
}
}
g_odata[bx*threads+tid]=sum;
}
Так как размер текстур в Geforce 8800 ограничен 8192x8192, то тесты проводились на текстурах float1 этого размера и на текстурах float4 размером 4096x4096. Объем выбираемых данных, таким образом, составлял 256 мегабайт, в 2.25 раза меньше чем в тестах на прямую выборку из global memory. Вследствие этого, точность получаемых данных меньше (время исполнения меньше, а точность его измерения и overhead остались прежними).
Общие результаты
В таблице приведены максимальные скорости чтения, достигнутого для разных способов чтения и порядка выборки.
| NVidia 8800GTX: скорость чтения из глобальной памяти, текстурная выборка (Гбайт/сек) | ||
|---|---|---|
| Тип данных | порядок обхода | |
| по строкам | по столбцам | |
| FLOAT | 42.26 | 46.12 |
| FLOAT4 | 70.98 | 64.47 |
Результат крайне интересный:
- "оптимальный" порядок обхода с выборкой float1 дал наименьшую скорость. Скорость выборки составляет 57% от случая некэшированной выборки (из глобальной памяти).
- Все прочие случаи существенно быстрее, чем для прямолинейной некэшированной выборки с теми же параметрами (направление обхода, тип выбираемых данных), более того скорость выборки float4 при вертикальном обходе практически равна скорости некэшированной выборки по строкам.
Изучение параметров мультизадачности
Как и в предыдущем случае, мы можем регулировать два параметра:- Количество threads в блоке (рекомендуют кратно 32).
- Количество блоков (рекомендуют чем больше, тем лучше).
Количество threads в блоке
Оптимальная производительность достигается при разных параметрах execution grid:- горизонтальная выборка:
- float1: 4096 блоков, 64 thread.
- float4: 2048 блоков, 32 thread.
- вертикальная выборка:
- float1: 4096 блоков, 64 thread.
- float4: 1024 блока, 64 thread
Объяснение очень простое: чем больше threads в блоке, тем меньше локальность обращения, тем больше вероятность cache miss.
Если построить график зависимости bandwidth от количества threads для 4096 блоков и горизонтальной выборки по 4 байта, мы увидим картину, которая существенно отличается от прямого чтения:
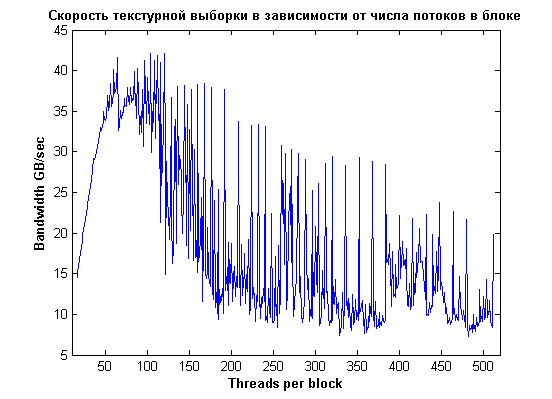
Оптимальное число тредов: 64 или 128. При увеличении числа тредов средняя производительность монотонно падает (ее нужно рассматривать отдельно для числа тредов кратного 32/16/8/4 из-за разницы в выравнивании).
Скорости невыровненного (т.е. псевдослучайного) чтения существенно выше, чем при прямой выборке, хотя чтение выровненых данных в любом случае быстрее.
Отдельное внимание следует обратить на скачкообразный рост скорости невыровненного (при числе тредов некратных 32) чтения при более чем 384 потоках. Объяснение достаточно простое: вместо двух исполняемых CTA на мультипроцессоре
остается только один блок, что увеличивает локальность чтения из кэша.
Количество CTA
Зафиксировав число threads per block на значении 128, построим график зависимости скорости исполнения от количества CTA. Чтобы не захламлять картинку, нарисуем сначала каждую 16-ю точку: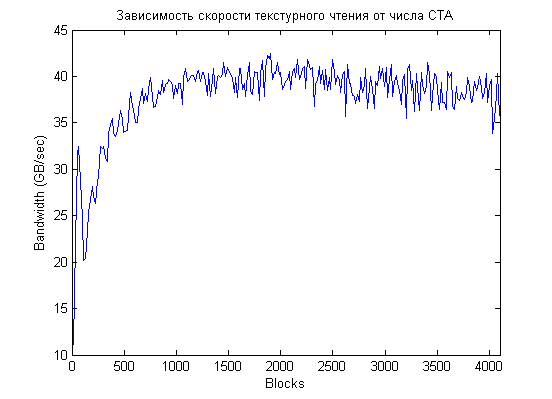
Как прекрасно видно из графика, "зависимость сложная", первый максимум достигается для 64 CTA, затем идет более-менее монотонный рост с максимумом на 1904 блоках (это 119 CTA на мультипроцессор!), затем начинается постепенное падение.
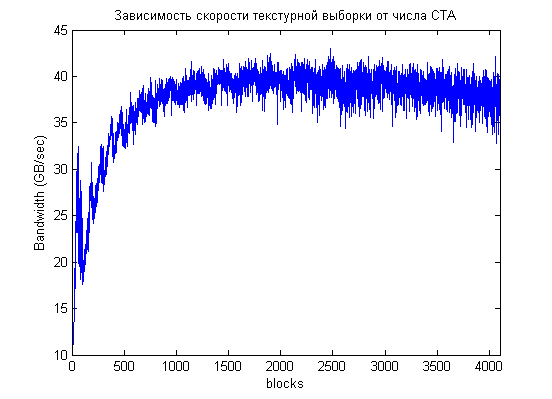
Если рассмотреть все данные, а не каждую 16-ю точку, то видно, что реальная картина еще более сложная, но общая зависимость сохраняется, оптимальное количество CTA порядка 2000 (и кратно 16):
Если рассмотреть только начальную часть графика, то мы увидим там локальные максимумы на 64, 96, а затем с шагом 96 CTA (192, 288, 384, 480):
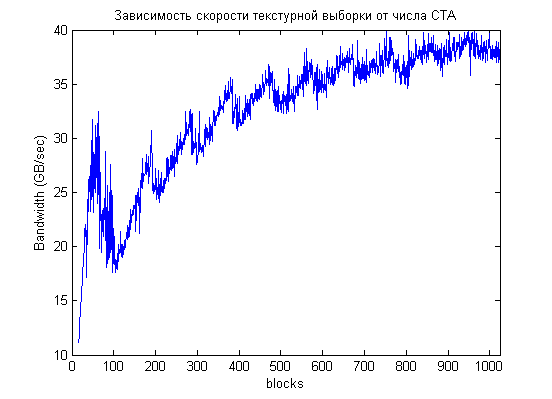
Можно (сугубо умозрительно) связать это с тем фактом, что ширина шины данных 48 байт (384 бита), из DDR-памяти приятно читать по два такта за раз т.е. по 96 байт. Т.е. за 4 такта будет удобно вычитать данных для 96 потоков.
Заключение
- Текстурное чтение может быть отличной альтернативой выборке из global memory в случае псевдослучайного доступа или доступа по столбцам. Собственно, про это написано в документации.
- Оптимальные параметры execution grid при использовании текстурной выборки определяется не только соображениями оптимальной многозадачности, но и параметрами кэша текстур: крайне желательно следить за локальностью чтения.
- Судя по результатам, кэширующий юнит больше любит локальность по строкам, а к локальности по столбцам относится спокойнее (вертикальный prefetch делается на большее расстояние). Вследствие этого, для используемого метода обхода входных данных (разные CTA обрабатывают разные строки, а threads внутри CTA идут по строке), оптимальными оказались параметры execution grid, отличающиеся от оптимальной сетки для прямой выборки:
- Выгодно увеличивать количество CTA (до, примерно, 2000). Для прямой выборки оптимальное количество CTA равно 512.
- Выгодно ограничивать количество threads в CTA до 64 (а в некоторых случаях и до 32). Для прямой выборки оптимальное количество потоков было 384.
- Резюмируя: для текстурной выборки важнее удовлетворить texture cache, а не остальные части системы.
Comments
Спасибо.
Спасибо.