NVidia 8800GTX: пропускная способность памяти (при использовании CUDA)
Из общих соображений, понятно что самая медленная часть суперкомпьютера - память. С одной стороны, теоретическая пропускная способность (bandwidth) составляет 900MHz * 384 бита * 2 (DDR) = 86.4 GB/sec. С другой стороны, раздел 6.1.1.3 руководства говорит о 200-300 циклах memory latency (при, по всей видимости,случайном доступе).
К счастью, проблема легко изучается: если взять достаточно много данных (скажем, полгигабайта) и, например, сложить все 4-байтовые значения (как float), то основные затраты времени будут именно на чтение из памяти, а всей прочей арифметикой можно пренебречь (или подсчитать ее отдельно).
Соображения
- Чтения из global memory могут быть 64- и 128-битными (раздел 6.1.2.1), руководство по программированию рекомендует выравнивать чтения блока тредов (точнее, warp-а) на 16*sizeof(type) байт - в этом случае обещается одновременная загрузка всех данных для всех тредов.
- Количество threads в блоке рекомендовано иметь 64, а лучше 192 или 256 (раздел 6.2). При этом:
- размер warp-а (набора одновременно выполняемых threads) для Geforce 8800 равен 32 threads
- блоки threads могут выполняться на одном мультипроцессоре одновременно (как я понимаю, целым числом блоков)
- задержки при read-after-write регистра не чувствуются (прячутся scheduler-ом) при числе тредов на мультипроцессоре >192.
- максимальное количество threads на мультипроцессор (одновременно): 768.
- выбирая количество threads в блоке следует учитывать использование локальной shared memory и локальных регистров. В частности, размер Register File на мультипроцессор составляет 32 килобайта, следовательно для запуска 768 threads (максимальное количество) использование регистров в kernel должно быть не более 10 (регистры 4-байтовые). Посмотреть использование регистров можно в файле с расширением .cubin, который останется в каталоге компиляции, если компилятору дать ключик -keep (там же образуется и крайне интересный файл .ptx с ассемблерным листингом).
- Количество thread blocks (CTA) должно быть достаточно большим. Руководство по программированию говорит о "не менее 100"
(раздел 6.2), а "1000 будут достаточны на несколько поколений оборудования". Сотрудники NVidia в личной переписке более
конкретны:
- CTA должно быть не меньше чем мультипроцессоров (которых на 8800GTX 16 штук).
- А лучше больше чем мультипроцессоров или(и?) кратно их числу.
- Не меньше общего числа CTA, способных одновременно исполняться (см. выше: количество одновременно исполняемых CTA определяется register usage и общим числом threads).
- Кратно числу CTA, способных одновременно исполняться
Сама по себе модель исполнения на G80 — "много тредов в блоке, много блоков и все это как-то диспетчеризуется с возможностью синхронизации только внутри блока" — в голове укладывается плохо, нужны эксперименты.
Тестовая задача
Возьмем "квадратный массив", влезающий в память видеокарты. Желательно, чтобы размер был бы кратен степени двойки. Размер 12288x12888 всем хорош: это 600 мегабайт данных (для типа float или int), размер кратен 212. Проинициализируем массив переменным паттерном чисел по порядку величины около 1:{
data[i]= 1.0+(SIZE*SIZE-i-1)/((float)SIZE*SIZE);
data[i+1]= 1.0-2.0*i/((float)SIZE*SIZE);
data[i+2]= 1.0+3.0*(SIZE*SIZE-i-1)/((float)SIZE*SIZE);
data[i+3]= 1.0-2.0*i/((float)SIZE*SIZE);
}
Складывать все числа массива можно разными способами:
- Порядок обхода:
- по строкам
- по столбцам
- Выборка данных:
- 4 байта (одно float число)
- 16 байт (один вектор float4)
Sum_h(int run,FTYPE *g_idata, float *g_odata)
{
const unsigned int blocks = gridDim.x;
const unsigned int threads = blockDim.x;
const unsigned int tid = threadIdx.x;
const unsigned int bx = blockIdx.x;
unsigned int rowN,colN;
float sum = 0.0;
for(rowN=bx; rowN < SIZE; rowN+=blocks){
for(colN=tid; colN < SIZE; colN+=threads){
sum += g_idata[rowN*SIZE+colN];
}
}
g_odata[bx*threads+tid]=sum;
}
Перед исполнением тестового кода выполняется вызов пустого kernel (с одним небольшим циклом и записью результатов в выходной массив), время исполнения которого (это 0.03-0.5 миллисекунды, в зависимости от количества блоков и тредов) вычитается из времени исполнения измеряющего вызова.
Первые результаты
В таблице приведены максимальные скорости чтения, достигнутого для разных способов чтения и порядка выборки.
| NVidia 8800GTX: скорость чтения из глобальной памяти (Гбайт/сек) | ||
|---|---|---|
| Тип данных | порядок обхода | |
| по строкам | по столбцам | |
| FLOAT | 70.52 | 0.92 |
| FLOAT4 | 38.83 | 3.73 |
Как видим, чтение по 4 байта по строкам дает 82% скорости от теоретического максимума, прекрасный результат как по абсолютному значению (на порядок быстрее того, что удается намерять на Intel Woodcrest и в ~7 раз быстрее memory bandwidth для Opteron), так и в доле от теории (у того же Woodcrest теоретическая полоса около 21Gb/sec, а практическая - около шести).
Доступ по столбцам дает максимально неэффективный доступ, это те величины, которых следует ожидать и при случайном доступе.
Цифры для FLOAT4 объяснимы лишь частично:
- доступ по столбцам вчетверо лучше, чем для единичного FLOAT. Все совершенно прозрачно, загрузка 32 бит и 128 бит занимают одинаковое время, но во втором случае читается вчетверо больше.
- Для чтения по строкам: я грешу на большую потребность thread-а в регистрах (4 регистра на чтение промежуточных значений и до 3 регистров на промежуточные результаты сложения), отчего количество одновременно исполняемых на мультипроцессоре threads должно было упасть.
Предварительные выводы
- При последовательном доступе к памяти выгодно не выпендриваться и читать не больше данных, чем нужно.
- Неоптимальный (по столбцам) доступ к памяти крайне нежелателен, скорость доступа снижается почти на два порядка.
- Если доступ по столбцам все-таки нужен, то выгоднее читать по 128 бит за чтение (т.е. делать это до такой степени "по строкам", до какой это возможно).
Оптимальные параметры мультизадачности
Для рассматриваемой задачи мы можем менять два параметра:- Количество threads в блоке (рекомендуют кратно 32).
- Количество блоков
Количество threads в блоке
Если не вдаваться сильно в детали, то для 8800GTX начиная с 32 блоков и 256 threads в блоке, либо с 64 блоков и 128 threads мы достигаем практически максимальной скорости.16 threads - далеко от оптимума (разница в 3-4 раза от оптимума), 32 threads - тоже недостаточно (разница в 1.5-2 раза).
Максимальная скорость была достигнута для 192 threads и 1024 blocks. Максимум на 384 threads (почти такой же, как для 192) показывает, что удалось загрузить мультипроцессоры полным количеством потоков.
Если запускать тестовую задачу с числом потоков, меняющихся на 1 (от 16 до 512), то становится понятной важность выравнивания хоть на что нибудь:
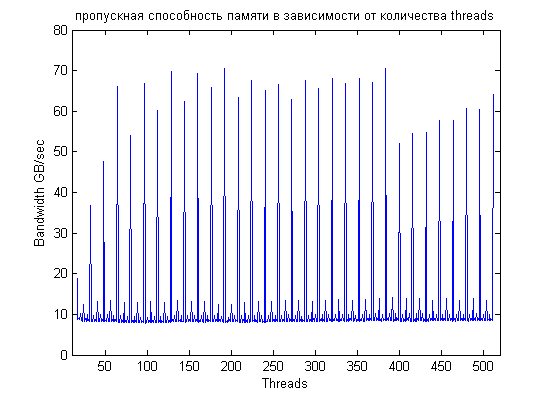
Для количества threads, некратного 16-ти, пропускная способность очень плохая (в сравнении с легко достижимым при правильном выравнивании идеалом) - порядка 10Gb/sec вместо 65-70.
Bandwidth кое-как подрастает для числа threads кратного 4-м (что соответствует выравниванию на 16 байт) и заметно подрастает для количества потоков,
кратного 8-ми. Между кратностями 16 и 32 тоже есть заметная разница (можно сравнить, например,
96-112-128 или 256-272-288), но на мой взгляд она уже определяется оптимальностью диспетчиризации по 32 thread.
Весьма интересен резкий спад в производительности сразу после 384 thread, он отвечает ситуации, когда на одном мультипроцессоре начинает работать только один CTA (до 384 включительно их было два и более).
Количество блоков threads
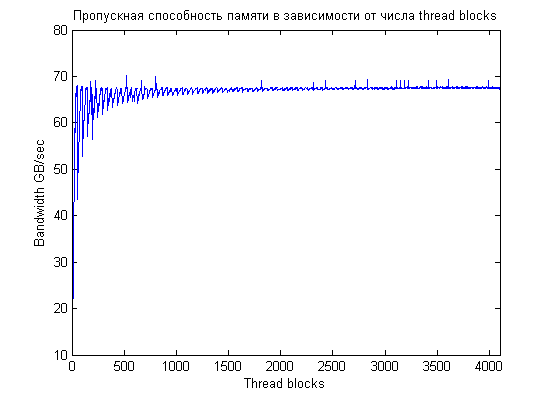
Предпочтения по выбору количества блоков (CTA) описаны выше, но несложно оценить реальное влияние количества thread blocks на скорость работы.Для чтения по строкам, изменение количества блоков не влияет на выравнивание: каждый блок обрабатывает целое количество строк (и это количестсво между блоками не различается более чем на 1), а строки выровнены на 16 килобайт. В то же время, количество блоков, некратное числу исполняющих мультипроцессоров приведет к частичному простою мультипроцессоров.
Из графика видно, что при числе блоков до ~1024 наблюдаются заметные скачки производительности в зависимости
от количества CTA:
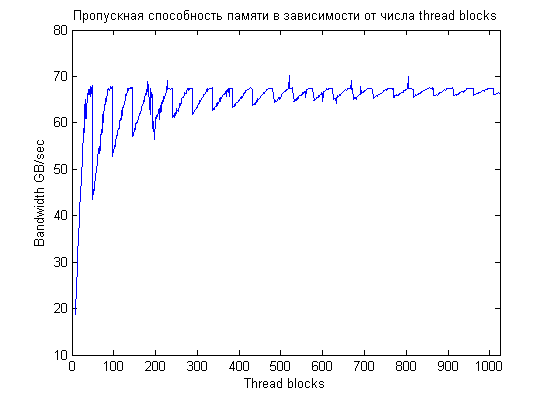
Если рассмотреть левую часть графика более детально, то видно что для небольшого количества CTA правильный выбор числа блоков весьма важен, производительность скачет на 15-20%. Чем больше блоков, тем меньше скачки, что и ожидалось:
Помимо пилообразного графика, мы видим пики максимальной производительности для 256, 512, 640, 768 блоков.
Заключение
По мере уменьшения степени влияния на производительность чтения из глобальной памяти:- Наиболее важным для получения большой производительности является порядок чтения. Обход по столбцам (т.е. фактически псевдослучайная выборка) крайне неэффективен, потери производительности в сравнении с обходом по строкам составляют почти два десятичных порядка. Правильный порядок обхода позволяет получить скорость чтения более 70 Gb/sec, что крайне неплохо в сравнении с теоретически-возможным значением.
- Неправильное количество threads в CTA ведет к неправильному выравниванию доступов к данным и, как следствие, к провалу производительности в разы. Количество threads в CTA желательно иметь кратным 32-м, а лучше 64-м, при этом равным 192 и более. Оптимальное количество threads, конечно, ограничивается использованием регистров.
- Использование 128-битных типов данных ведет к 1.5-2-кратному провалу в производительности при чтении по строкам и к 4-кратному росту производительности при чтении по столбцам. Таким образом, при необходимости читатьпо столбцам float4 может немного помочь.
В принципе, чтение по столбцам должно быть сильно быстрее при чтении текстур: там есть 2D-кэш, оптимизированный под такое чтение. Но это - тема отдельного исследования т.к. быстро совладать с текстурами не получилось
Оптимальные значения
- Много CTA - хорошо. Причем их количество хорошо бы иметь пропорциональным какой-нибудь степени двойки. В рассматриваемой задаче максимальная производительность достигнута при 256, 512, 640 и 768 блоках.
- Много threads - тоже хорошо. Для threads крайне важно, чтобы доступ к глобальной памяти был выровнен, количество threads в блоке полезно иметь кратным 32-м, для сокрытия латентности регистров полезно иметь более чем 192 thread на мультипроцессор (это достигается или увеличением числа thread в блоке, либо увеличением числа одновременно исполняемых CTA). Наилучшая производительность была получена для 192, 256, 320, 384 threads per CTA.
Comments
В нашей задаче нужно сделать очень много одинаковых независи
В нашей задаче нужно сделать очень много одинаковых независимых вычислений (с разными входными данными), то есть для одного запуска программы -- сотни тысяч раз. Однако каждое вычисление, довольно сложная процедура, включающая инвертирование небольших матриц, и всевозможные другие матрично-векторные операции небольших размерностей. Как думаете, лучше поступить, в каждом кернеле делать весь алгоритм (но тогда он заведомо сожрет все регистры и shared memory и их много параллельно не исполнится) или же, просто последовательно использовать cublas для каждой матричной операции (проблема то только в том, что матрицы всего лишь размера где то 32х32, боюсь на них cublas особенно ничего не даст). Уж очень не хочется писать на CUDA свое инвертирование матриц...
Очень сложно лечить болезнь по телефону. По идее, если пара
Очень сложно лечить болезнь по телефону.
По идее, если параллельные задачи и разные данные - надо бы пускать в параллель. Если не получается - пилить на максимально длинные подзадачи.
Обращение матриц делать, конечно, мучительно, но получится ли без него ? Нельзя эти матрицы собрать в одну большую, чтобы ее можно было бы обратить как одно целое ?
Алексей, здравствуйте, я совсем недавно столкнулся с CUDA и
Алексей, здравствуйте, я совсем недавно столкнулся с CUDA и еще не до конца разобрался во всех премудростях работы с данной технологий.
В Вашей статье главным образом рассматривается скорость чтения как основная проблема в производительности, а как быть со скоростью записи? Относятся ли к записи в память все те же правила оптимизации, что и к чтению (проверить на практике еще не успел)? Или есть какие либо другие способы увеличить скорость записи в память?
Я решаю следующую задачку: есть два линейных массива X (1.5 млн. элементов) и Y(100 тыс.)- нужно сравнить каждый элемент X с каждым Y и результат сравнения записать в массив Z размерностью SizeX*SizeY. В результате экспериментов выяснилось что основная проблема быстродействия это сохранение результатов - 20 мин против 1 минуты без записи результата на массивах указанной размерности. Может быть подскажите куда копать?
Сергей, да, естественно, с записью в global memory будут те
Сергей,
да, естественно, с записью в global memory будут те же проблемы, что и с чтением. Нужно писать 'coalesced' способом, т.е. одновременно из разных тредов в соседние элементы. Тогда вы скорости в десятки гигабайт в секунду скорее всего достигнете. Но это в случае, если вы из каждого thread пишете 4-байтовые слова.
Если же у вас на выходе битовая матрица, то придется организовывать работу так, чтобы запись в global memory была именно 4-байтовыми словами.
Но главное узкое место будет даже не запись в global memory, а вывод обратно на хост. Если в global memory можно (предположительно) писать десятками гигабайт в секунду, то download из карты - около гигабайта в сек. Прикидываем на пальцах - полтора миллиона * 100 тысяч * 4 байта - 600 гигабайт. Во-первых, эти 600 гигабайт надо куда-то деть на хосте, а во-вторых они будут передаваться минут 10 сами по себе.
Вообще, для задач с низкой арифметической сложностью (отношение вычислений к чтениям или записям памяти) перенос их на видеокарту не имеет большого смысла, весь выигрыш от быстрой памяти съест передача данных туда и обратно.
Алексей, большое спасибо за подсказки и за статью, благодар
Алексей,
большое спасибо за подсказки и за статью, благодаря им удалось увеличить скорость обработки на порядки. Изменение порядка чтения и записи помогло :-)
Насчет задач с низкой арифметикой вы правы, перенос остальных расчетов на карту - следующий этап, пока хочется разобраться с более простой задачей, хотя уже сейчас у меня не просто сравниваются два значения а, они сравниваются побитно по хитрому алгоритму - эта процедура на CPU занимает очень много времени из-за чего собственно и встал вопрос использования GPU
Алексей, огромное спасибо за интересную статью! У меня при
Алексей,
огромное спасибо за интересную статью!
У меня при работе с CUDA на 8800GTX возникли странные сложности с глобальной памятью :(
Задача: есть текстовый файл ~50Мб, есть словарь из 16384 слов, надо найти индексы первого вхождения каждого из этих слов, т.е. осуществить поиск. Естественно первое, что пришло на ум: запустить N блоков по M тредов, чтобы M*N=16384 параллельных тредов. Так и сделал. Но вот беда: при поиске в 50Мб выдаёт, что ни одного слова не нашёл (алгоритм - банальный брутфорс).
Тогда я сократил задачу и сделал 1 блок с 1 тредом в грайде (однопоточный поиск соответственно только 1-го слова из словаря, в файл в котором ищем вписал это слово в самый конец) - получилось то же самое :(
Затем я заменил в цикле брутфорса j=0 на j=40000000 и слово было найдено (производительность пока пофиг)!
Получается очень странно - по идее если мы выделим память с помощью cudaMalloc() и скопируем в неё из хоста - все потоки должны этот массив видеть _полностью_ , так ? А у меня все потоки видят только "по 10 мегабайт" (если слово поставить в пределах первых 10 Мб и вернуть j=0 - тоже находит).
Где могут быть "грабли" при работе с глобальной памятью?
Может есть какие ограничения?
P.S. Собсно вот исходник самого поиска для 1 треда:
//
// char *x - указатель на массив с искомым словом
// int m - длина массива x
// char *y - указатель на массив с текстом
// int n - длинна массива (50000000 байт в моём случае)
// int *r - указатель на массив с результатами (позиция в файле)
//
// все указанные выше массивы скопированы с хоста на девайс
// c помощью cudaMemcpy(), т.е. находятся в глобальной памяти девайса.
//
__device__ void BF(char *x, int m, char *y, int n, int* r)
{
int i, j;
*r = -1;
for (j = 0; j <= (n-m); j++)
{
for (i = 0; ((i < m) && ( *(x+i) == *(y+j+i) )); i++);
if (i >= m)
{
*r = j;
break;
}
}
}
//
// А это wrapper
//
__global__ void BFWrap(char *dict, int *offsets, char *y, int n, int* r)
{
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int sid = bid * NUM_THREADS + tid;
if(offsets[sid+1]>0)
{
BF(dict+offsets[sid], offsets[sid+1] - offsets[sid] - 2, y, n, r+sid);
}
}
из main() запускаю его так:
BFWrap<<>>(d_ddata, d_odata, d_idata, textSize, d_rdata);
NUM_BLOCKS и NUM_THREADS за'define'ны и равны 1, т.е. я даже не пользую многпоточность и всё равно не работает :(
Попробовал тупое копирование: h_idata -- cudaMemcpy() -
Попробовал тупое копирование:
h_idata -- cudaMemcpy() --> d_idata
d_idata -- __global__ Copy() --> d_odata()
d_odata -- cudeMemcpy() --> h_odata
Результат у исхоника, приведёного ниже 50/50 (т.е. то работает, то не работает). Если уменьшать размер memSize - стабильность работы возрастает.
// includes, system
#include stdlib.h
#include stdio.h
#include string.h
#include math.h
#include time.h
#include windows.h
// includes, project
#include cutil.h
#include cuda.h
#define NUM_BLOCKS 1
#define NUM_THREADS 1
__global__ void Copy(char *from, char *to, int n)
{
for(int i=0; i "меньше" n; i++) to[i] = from[i];
to[0] = '1';
to[n-1] = '2';
}
int main(int argc, char** argv)
{
unsigned int memSize = 30000000;
FILE *F;
// host vars
char *h_idata = NULL;
char *h_odata = NULL;
// device vars
char *d_idata = NULL;
char *d_odata = NULL;
CUT_DEVICE_INIT(argc, argv);
//pinned memory mode - use special function to get OS-pinned memory
CUDA_SAFE_CALL( cudaMallocHost( (void**)&h_idata, memSize ) );
CUDA_SAFE_CALL( cudaMallocHost( (void**)&h_odata, memSize ) );
//allocate device memory
CUDA_SAFE_CALL(cudaMalloc((void**)&d_idata, memSize));
CUDA_SAFE_CALL(cudaMalloc((void**)&d_odata, memSize));
//initialize the memory
F = fopen("out.txt", "rb");
memSize = fread(h_idata, 1, memSize, F);
fclose(F);
//copy host memory to device memory
unsigned int timer = 0;
float elapsedTimeInMs = 0.0f;
CUT_SAFE_CALL( cutCreateTimer( &timer ) );
CUT_SAFE_CALL( cutStartTimer( timer));
// copy host to device
CUDA_SAFE_CALL(cudaMemcpy(d_idata, h_idata, memSize, cudaMemcpyHostToDevice));
// copy inside device
Copy "тут 3 меньше"NUM_BLOCKS, NUM_THREADS"тут 3 больше"(d_idata, d_odata, memSize);
CUDA_SAFE_CALL(cudaThreadSynchronize());
// copy device to host
CUDA_SAFE_CALL(cudaMemcpy(h_odata, d_odata, memSize, cudaMemcpyDeviceToHost));
CUT_SAFE_CALL( cutStopTimer( timer));
elapsedTimeInMs = cutGetTimerValue( timer);
printf("Elapsed: %f seconds\n", elapsedTimeInMs / (float)1000);
// write to file
F = fopen("output.txt", "wb");
fwrite(h_odata, 1, memSize, F);
fclose(F);
//clean up memory
CUDA_SAFE_CALL(cudaFreeHost(h_idata));
CUDA_SAFE_CALL(cudaFreeHost(h_odata));
CUDA_SAFE_CALL(cudaFree(d_idata));
CUDA_SAFE_CALL(cudaFree(d_odata));
CUT_EXIT(argc, argv);
}
В документации про глобальную память вроде ничего про ограничения не сказано... Что я не так делаю в этом простом копировании???