Ну, за репрезентативность
В кулуарах Хайлоада представители Спайлога не стеснялись утверждать, что их тренды - репрезентативны, а глобальная статистика - хороша. Не хочется обижать хороших людей, но правда дороже.
Вот как выглядит верхушка топа поисковиков за октябрь по версии Spylog Тренды:
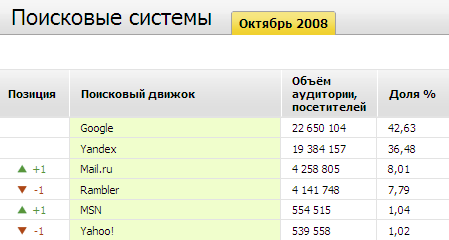
Эти данные неплохо согласуются с полной статистикой LiveInternet, но вот данные о поисковых фразах заставляют задуматься о репрезентативности всей конструкции.
Яндекс недавно опубликовал отчет Поиск в интернете: что и как ищут пользователи (осень 2008) (прямой линк на PDF-версию), Top-10 поисковых запросов по версии Яндекса выглядят так:

Оно все довольно ожидаемо - почти сплошные навигационные запросы плюс пара частотных информационных.
Смотрим теперь на статистику liveinternet по переходам с поисковиков, за октябрь, ибо изучаем мы Spylog, а там тоже за октябрь:
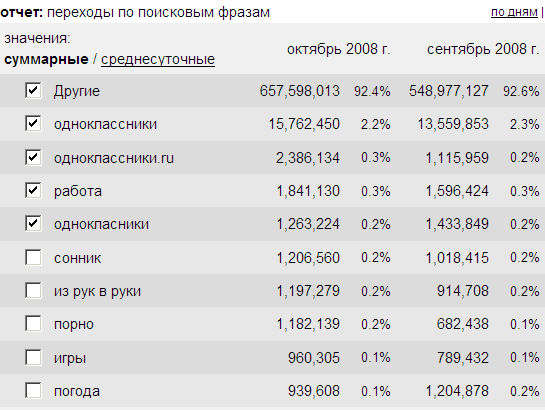
Никаких чудес, некоторых получателей навигационного трафика в Li.ru нет (ВКонтакте, Mail.ru, зайцев тоже нет), соответственно статистика по переходам на них - отсутствует. Но общая картина не вызывает отторжения и довольно близка к Яндексовской.
Может быть у Гугла другой трафик? Да, немножко другой: спрашивают photofunia, 4shared. Впрочем, если смотреть не верхнюю десятку, а верхние 50, то трафик с Гугла очень похож на Яндексовский, все те же вечные ценности: погода, порно, рефераты, музыка, футбол, MP3 и анекдоты.
Смотрим теперь в десятку поисковых запросов по версии Spylog:
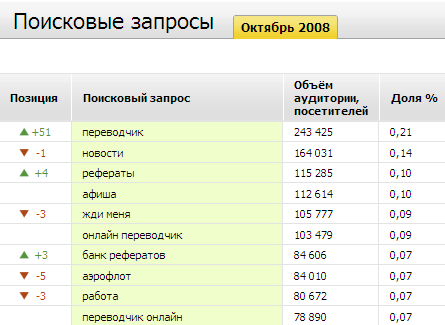
Я извиняюсь, вы сказали переводчик? Нет, переводчик отличный частотный запрос, если поискать его в статистике запросов Яндекса, то место его - в хвосте первой полусотни по частоте. Но уж всяко не выше новостей-погоды-рефератов. Онлайн переводчик, который у Spylog тоже в десятке, запрос еще менее частотный, место ему во второй сотне по частоте.
Кроме того, оный переводчик вылез на 1-е место с 52-го (где ему и место) - по итогам октября. Очевидно, в систему учета добавили один (прописью) сайт, просто с большим трафиком. Скорее всего, этот сайт - translate.ru (счетчик Spylog там есть). Если один сайт с посещаемостью около 200 тыс. посетителей в сутки (большая, но не запредельная) выводит свой основной запрос на первое место, это вызывает вопросы.
При этом, сумма частот первой десятки по Spylog - довольно большая, около процента. Для запросов не из самого верха списка - это слишком большая суммарная частота, если бы Рунет репрезентовался нормально, было бы меньше.
Все вышесказанное не позволяет считать поисковую статистику Spylog репрезентативной. Liveinternet - тоже не вполне репрезентативен, но там выпадения в высокочастотной части объяснимы, а остаток не вызывает такого отторжения.
Comments
Ни на gismeteo.ru, ни на hmn.ru - счётчика спайлога не стоит
Ни на gismeteo.ru, ни на hmn.ru - счётчика спайлога не стоит, так что погода пролетает, это ожидаемо. А вот на translate.ru стоит, имеем "переводчик". Меня вот гораздо больше удивляет сонник на li.ru - но наверное этому тоже есть какое-то логичное объяснение.
На самом деле отторжение у тебя наверняка вызывает в первую очередь отсутствие слова "порно". В спайлоговской статистике его нет по построению - в выборку, по которой строятся тренды, порносайты не включаются.
У меня вызывает отторжение то, что не очень крупный сайт (20
У меня вызывает отторжение то, что не очень крупный сайт (200k посетителей - это заметно, но сколько из них попадает через поиск?) дал слову +51 позицию и вывел на первое место.
Пятое место в списке слов тоже очень показательно - то, о чем я подумал имеет посещаемость меньше 15 тысяч в день, а реальное место этого запроса - не пятое, а примерно двухсотое.
Жди меня? Они насколько я помню размножались поисковыми запр
Жди меня? Они насколько я помню размножались поисковыми запросами в Рамблере, вплоть до призывов в эфире, так что это может быть вполне объяснимо.
Ну и опять же не забывай, что это *посетители*. Т.е. внешние по отношению к интернету факторы влияют куда заметнее, чем внутренние.
Вообще не подумайте что я защищаю глобальную статистику по поисковым фразам как таковую. IMHO она в отрыве от конкретного ресурса имеет мало смысла, и сильно подвержена влиянию всяких очень странных факторов.
Даже если у "жди меня" все 100% трафика - это поис
Даже если у "жди меня" все 100% трафика - это поисковый по этой фразе, наличие их в вашем top10 удручает. Ибо эти 100% - на самом деле очень немного.
Обсуждаем репрезентативность.
Ну я типа пытаюсь продвигать мысль, что частотные запросы в
Ну я типа пытаюсь продвигать мысль, что частотные запросы в современном интернете - это навигационные запросы, и репрезентативности по ним быть не может по определению. А вылезшая наверх навигация на ресурсы с относительно небольшим реальным трафиком - это как раз показатель доли поискового трафика у этих ресурсов.
Надо будет посмотреть как меняется картинка если статистику строить не по пресловутой выборке, а вообще по всему что есть.
BTW, заметил прикольную багу - в графе "Прочее" на трендах - цена на дрова. Послал лучи ответственным.
новости-порно-погода-рефераты - это не навигационные запросы
новости-порно-погода-рефераты - это не навигационные запросы. И переводчик - тоже, кстати.
Вообще, если взять верхушку из liveinternet и сопоставить им чистые частоты - то картина не будет столь ужасающей (и по навигационным запросам тоже), как у вас.
Проблема не в том что думают люди когда вводят запросы, а в
Проблема не в том что думают люди когда вводят запросы, а в том куда они в результате попадают. Про погоду я уже писал выше. Т.е. фактически - нет счётчика на одном-двух сайтах - запрос из топов вылетает.
С новостями и рефератами - пока не так, но они у нас и стоят в десятке.
Я не утверждаю что у нас лучше чем в liveinternet'е, очевидно что у них сейчас охват больше. Но в целом IMHO у нас не то чтобы очень плохо.
"Ну ужас конечно. Но не ужас-ужас-ужас." (c) :)
Ну вот смотри - по навигационным запросам (верхушке) - нереп
Ну вот смотри - по навигационным запросам (верхушке) - нерепрезентативны.
По информационным - опять по верхушке - та же фигня (погоду, игры и порно - зафильтровали, а остальное лезет какое-то очень случайное (ну вот аватары на 20-м месте).
А показываете вы - маленький кусочек. Вот что показали публично - нерепрезентативно (аэрофлот выше работы?).
Что там при этом с распределением по поисковикам - неясно. Ну вот признали, что по словам фильтруете, чтобы порно не пролезло. И, значит, настаиваете, что фильтрованая статистика - очень даже хорошая.
Сонник, кстати, частотный запрос. Примерно вдвое более часто
Сонник, кстати, частотный запрос. Примерно вдвое более частотный, чем переводчик. Частота практически одинаковая с irr, что нам li.ru и показывает.
сонник - 501559 показов в месяц http://wordstat.yandex.ru/ad
сонник - 501559 показов в месяц
http://wordstat.yandex.ru/advq?rpt=ppc&key=&shw=1&tm=&checkboxes=&text=%...
переводчик - 689942 показов в месяц
http://wordstat.yandex.ru/advq?rpt=ppc&key=&shw=1&tm=&checkboxes=&text=%...
Я полностью согласен что Яндекс может врать куда больше чем все остальные фигуранты данного обсуждения, но ты вроде на него сам ссылался, нет?
Есть ещё версия что я Яндексом пользоваться не умею, поправь меня если что.
Это - рекламная частота. Т.е. "переводчик" по word
Это - рекламная частота. Т.е. "переводчик" по wordstat включает в себя и "онлайн переводчик" и всякие другие переводчики.
Чистая частота у переводчика - втрое (чуть больше) ниже.
Я правильно понимаю, что для получения "чистой" ча
Я правильно понимаю, что для получения "чистой" частоты надо из собственно цифры для слова вычесть сумму всех остальных на странице?
Не на странице, а на страницах, для переводчика я их 57 штук
Не на странице, а на страницах, для переводчика я их 57 штук насчитал.
Но не совсем так, потому что если у тебя такие запросы (3 штуки всего)
переводчик 100
онлайн переводчик 50
онлайн переводчик порно 20
то чистая частота переводчика будет 50, ибо третий запрос полностью всосан вторым (и как на самом деле Яндекс их складывает - мы только примерно знаем, запросов длиннее 5 слов в wordstat я не видел, а в жизни они есть и их много)
Ну и в wordstat тебе показывают все с частотой более 5, хотя для случая совсем частотного, вроде собственно переводчика - вклад совсем уж низкочастотки невелик (а вот например для слова nokia - похоже что очень велик).
Во первых порно-сайты не входят в выборку, по которой считаю
Во первых порно-сайты не входят в выборку, по которой считаются тренды, во втрорых на фразы стоит фильтр по словам, в частности названия сайтов(на сколько я помнию и брендов, за исключением брендов-омонимов типа афиша), нецензурные и непристойные слова(к сожалению некоторые не порно сайты умудряются соптимизироваться под слова типа зоо-по..) и т.д. попасть туда не могут.
По фразам думаю судить не стоит, т.к. их обработать можно очень по разному. Они не являются адекватной мерой сравнения.
Ну а уж сревнивать переходы с количеством посетителей вообще некорректно. Это уже обсуждалось, зачем повторяться?
У SpyLOG по переходам примерно такое соотношение между поисковиками как у Li. + можно пофильтровать по географии, а то с гугла из-за границы много народу ходит, на яндекс мало, см. http://presentation.mail.ru/RIW/Kedrov.ppt
Ну и конечно же, после прочтения некоторых аналитических обзоров, к которым приложил руку Алексей Тутубалин, не трудно понять его политические взгляды на Яндекс и Li.ru.
Ура, драка! Раз там все так репрезентативно, то почему аэро
Ура, драка!
Раз там все так репрезентативно, то почему аэрофлот выше работы?
Ещё раз, там стоит цифра, отражающая количество пользователе
Ещё раз, там стоит цифра, отражающая количество пользователей, а не запросов. Количество пользователей - это не частотность.
Значит больше народу запрашивало аэрофлот(по сайтам где стоит счётчик SpyLOG).
Работу запрашивают безработные, ищущие работу через интернет, их не так много, но запрашивают они её как правило не один раз по понятным причинам.
Те кто ищут аэрофлот - думаю должны найти его за один запрос, поэтому "аэрофлот" врятли попадёт в топ по переходам.
Ещё стоит учесть, что люди, которые ищут аэрофлот видимо летают и могут пользоваться разными компами с разными куками и в полне могут двоиться или даже троиться с статистике по пользователям.
P.S. Да, чего герха таить - мы все немного любим яндекс - вс
P.S. Да, чего герха таить - мы все немного любим яндекс - все немного патриоты :)
Ну если вы настаиваете на людях, то почему втб выше сбербанк
Ну если вы настаиваете на людях, то почему втб выше сбербанка?
Потому что на sbrf.ru не стоит счётчика SpyLOG.
Потому что на sbrf.ru не стоит счётчика SpyLOG.
Делает ли это выборку репрезентативной? Каких еще сайтов нет
Делает ли это выборку репрезентативной? Каких еще сайтов нет? Является ли ваше распределение по тематикам взвешенным?
Понимаете, одно дело взять просто несколько сотен тысяч сайтов (из нескольких миллионов), как это у Li.ru. У них даже очень крупные есть.
Другое дело - взять другие несколько сотен тысяч (без очень крупных) из тех же нескольких миллионов, а потом ее еще и пофильтровать по параметрам
- тематике
- посещаемости
- навигационным запросам
- части информационных запросов
- да еще все это не написать открыто, а выясняется это только при подробном допросе.
Что же вы удивляетесь, что над вами хихикают? Мне вот кажется, что это вы должны доказывать репрезентативность и несмещенность выборки при таком подходе.
Ну а главное - нафига фильтровать то? Зачем специально ухудшать выборку? У вас так много порно- и варезных сайтов?
Кстати по фразм топ по посетителям и по переходам будет силь
Кстати по фразм топ по посетителям и по переходам будет сильно отличаться даже у одного измерителя. У такого различия есть мого причин, прежде всего различие в поведении пользователей, в их активности. Например, есть фанаты "одноклассников", которые по каким-то причинам вбивают русское слово в поисковик вместо того, чтобы воспользоваться строкой браузера.
Поисковые фразы на трендах фильтруются, в частности, фраз "п
Поисковые фразы на трендах фильтруются, в частности, фраз "погода", "игры", "из рук в руки" и "порно" там не будет. Нефильтрованный top50 за октябрь выглядит так:
1:переводчик:243425
2:новости:164031
3:связной:151209
4:мтс:142716
5:евросеть:136029
6:рефераты:115285
7:афиша:112614
8:игры:107738
9:жди меня:105777
10:онлайн переводчик:103479
11:порно:95448
12:санрайз:91599
13:втб 24:85560
14:банк рефератов:84606
15:аэрофлот:84010
16:работа:80672
17:переводчик онлайн:78890
18:банк москвы:77500
19:консультант плюс:69577
20:одноклассники:69508
21:гороскоп:67105
22:знакомства:65453
23:iphone 3g:64886
24:футбол:59279
25:марафон:58990
26:почта россии:53939
27:loveplanet:53766
28:картинки:50627
29:aeroflot:49666
30:спортмастер:49033
31:iphone:48358
32:открытки:46599
33:nokia 5800:46513
34:rapget:46082
35:автомир:45745
36:дом 2:45211
37:мир:45055
38:секс:41849
39:тез тур:41781
40:онлайн игры:41487
41:download master:39978
42:аватары:39585
43:скачать музыку бесплатно:39453
44:коммерсант:39036
45:башорг:38933
46:artmoney:38698
47:втб24:38227
48:реферат:37076
49:ион:37061
50:промт:36208
О, платных клиентов спалили. Вот и объясняйте теперь, почем
О, платных клиентов спалили.
Вот и объясняйте теперь, почему "связной" выше рефератов и гороскопов. И, кстати, выше МТС.
Мой поинт - "вы нерепрезентативны", в части отчета по словам тут вообще никаких сомнений нет, в части остальных отчетов - можно обсуждать. Вы возражаете - и выкатываете отличный список слов с частотами, которые вообще ни в какие ворота.
(Это не говоря о том, что фильтровать что-то в "глобальной статистике" - это отличная идея).
А почему, кстати, погода фильтруется, а переводчик и новости
А почему, кстати, погода фильтруется, а переводчик и новости - не фильтруются?
О, да тут ещё народ подтянулся. А я как дурак сижу в жжшечк
О, да тут ещё народ подтянулся. А я как дурак сижу в жжшечке, там ничего этого не видно. :)
Вообще прикольные вещи выясняются. Надо будет прижать где-нибудь в углу аналитиков и поговорить сними про эти фильтры... Я то искренне полагал что там какая-то безобидная маторезка стоит... Бейсбольную биту не одолжишь? :)
Так нету же никакого мата в топ50. А порно - это жизнь, и ег
Так нету же никакого мата в топ50. А порно - это жизнь, и его у вас еще и меньше, чем вообще бывает.
Другой вопрос, что нефильтрованый список выглядит еще хуже и называть это "трендами" довольно опасно, засмеют.
А комментарии - да, у меня трансляция в одну сторону, с трансляцией в две есть всякие проблемы (в частности, я технологически не могу в ЖЖ сохранить авторство, даже если у меня человек авторизовался)
Дык я про то и говорю. Никакого мата нет, а фильтры непонятн
Дык я про то и говорю. Никакого мата нет, а фильтры непонятной этиологии - есть. Предпочитаю наблюдать неискажённую картину, какой бы она ни была.
Новости и рефераты, между прочим, всё в той же десятке. А наличие дополнительных навигационных запросов картину принципиально не меняет.
Относительно яндекса, который наше все, картинка очень сильн
Относительно яндекса, который наше все, картинка очень сильно смещена, это видно на глаз. Т.е. это вам надо доказывать что все хорошо, ибо переводчик смешит.
Да, тут не только с трансляцией проблемы... Вообще чудеса, к
Да, тут не только с трансляцией проблемы...
Вообще чудеса, когда я писал свой первый коммент, датированный 6-ю часами - примерно во столько и писал, видел только первый коммент mdounina, а вот сейчас гляжу - появилось много комментов, которые появились на свет намного раньше моего. Видимо был какой-то сбой сайта... Чудеса, да и только :)
Хорошо хоть сейчас прочитать можно :)
Да нет, просто комменты из ЖЖ забираются раз в час, а не в р
Да нет, просто комменты из ЖЖ забираются раз в час, а не в реалтайме.
ну видимо иногда раз в 5 часов бывает:) ничего страшного
ну видимо иногда раз в 5 часов бывает:) ничего страшного
Э, да, там может быть фигня с таймзоной, не задумывался. Пос
Э, да, там может быть фигня с таймзоной, не задумывался. Посмотрю, спасибо.
Макс, спущусь к тебе в понедельник. Удивлен фильтрам не мене
Макс, спущусь к тебе в понедельник. Удивлен фильтрам не менее твоего, проверю что режется.
Возвращаясь к теме репрезентативности в части поисковых запросов предлагаю признать, что Alex прав.
О большей репрезентативности можно говорить в части долей поисковых систем, географии, технометрики, аудитории, так как тренды строятся по месячным данным и здесь состав ресурсов менее критичен. Что мы и проверяли в сравнении с тем же liveinternet.
Сейчас в трендах участвуют топ 50 тыс. сайтов по размеру месячной аудитории. Берутся сайты в зонах ru и su, плюс в международных зонах с русскоязычным контентом. Исключаются национальные домены. Исключаются порнушники и варез. Это делается на автомате.
За репрезентативность поисковых фраз сможем бороться как только новый трекер поднимется. То, что перекосы вылезли - хорошо, видно что лечить нужно.
Я бы сказал, что репрезентативность выборки по поисковым сис
Я бы сказал, что репрезентативность выборки по поисковым системам можно будет обсуждать, если появится больше цифирок. Сравнивать 2-4 доли за месяц - ну что там сравнивать то, ну вот такие доли. Ну вот можно над переводчиком похихикать.
В этом смысле срезы Li.ru - они довольно хорошие т.к. позволяют этот куб данных посмотреть не с одной проекции, а с очень многих. Жалко что нету среза Google+RU, надо будет Зотова попросить при случае.
Касаемо вашей методики: отобрав 50 килосайтов - вы, по всей видимости, отсекли совсем уж idiot clicks (редкие случайные заходы на мелкие сайты). Было бы конечно здорово иметь два набора данных - по всей выборке (включая порно и варез), по выборке без порно и вареза и по этим 50K сайтов. Ибо есть гипотеза про толстый хвост по запросам (из публичных данных - есть отчет Яндекса) и если она верна и про сайты тоже, то уменьшение выборки может/должно сместить картину.
Хорошая мысль про хвосты, хотя про отсечение idiot clicks мо
Хорошая мысль про хвосты, хотя про отсечение idiot clicks можно поспорить.
При этом может вылезти отличие поискоых систем по предпочтению в зависимости от посещаемости сайта.
Вообще по словам у любого счётчика отчёт будет субъективным, т.к. наличие или отсутствие нескольких крупных сайтов по тематике может изменить вершушку. При этом, что обидно, складывать результаты двух счётчиков даже по переходам нельзя ибо есть сайты, использующие несколько измерителей.
Приходи, ага. Что до репрезентативности, то я тут как бы пы
Приходи, ага.
Что до репрезентативности, то я тут как бы пытаюсь сказать, что репрезентативность по навигационным запросам (а равно по "навигационной составляющей" информационных запросов) - вещь малореальная в принципе. Ибо выпадание даже одного сайта приводит к выпаданию запроса.
Соответственно при уменьшении выборки навигационные запросы начинают исчезать, до исчезновения сохраняя прежние цифры, а информационные - уменьшаются в количествах. Как результат - навигация лезет в топ.
Я вижу ровно два пути борьбы с этим - либо как алекса считать со стороны пользователей, либо - проанализировать и отделить навигацию (скажем - разбив выборку на случайные группы, и вычленить навигацию по различиям между группами).
А скажи мне, распределение "навигационные/информационные" у
А скажи мне, распределение "навигационные/информационные" у пользователей разных поисковиков/браузеров/операционок - одинаковое?
Про страны и вовсе не спрашиваю....
Подкину ребятам задачку, возможно получится посчитать что-то
Подкину ребятам задачку, возможно получится посчитать что-то осмысленное.
Вам для начала придется большой массив запросов расклассифиц
Вам для начала придется большой массив запросов расклассифицировать :)
Ну можно для начала пойти более простым путём - взять нескол
Ну можно для начала пойти более простым путём - взять несколько частотных тех и других, и посчитать по каждому разбивку по браузерам/операционкам. Но я тоже боюсь что гавно получится, и придётся сначала строить классификацию как я выше написал, да.
Я совершенно точно уверен, что для многих частотных информац
Я совершенно точно уверен, что для многих частотных информационных будет совершенно очевидные перекосы по браузерам-операционкам.
Хотя вот "портрет спрашивающего про iphone" - интересное исследование.